使用OpenAI开源的whisper来识别下casablanca及中文
OpenAI开源了其whisper有一段时间了,但大家更多关注的是其charGPT,这几天试了下whisper,觉得识别效果还是挺好的,针对中文,缺少的是其grammar的部分,或者说是中文汉语的一些语义及常用词等。还有一点可能就是里边没有把繁体和简体单独定义,所以常常会有一些繁体字在里边。
开源地址:https://github.com/openai/whisper.git
gitee镜像:https://gitee.com/nwaycn/whisper.git
识别效果图:
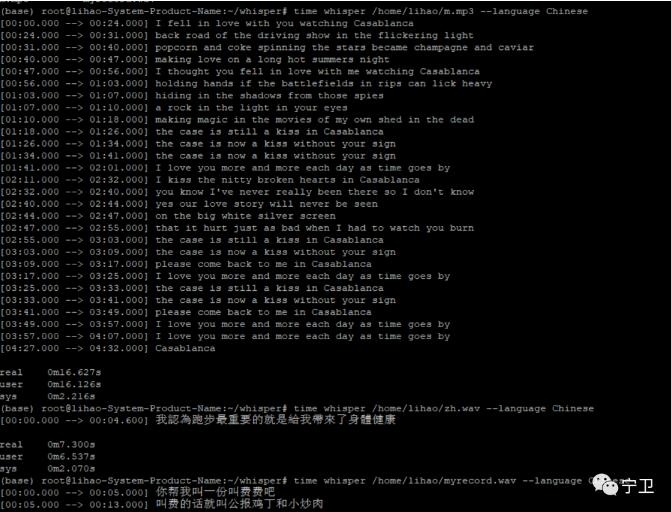
第一个文件为英文歌《casablanca》,后续两个是我们自己录制的中文语音文件。
下边我们再来首《我的未来不是梦》,看看识别结果
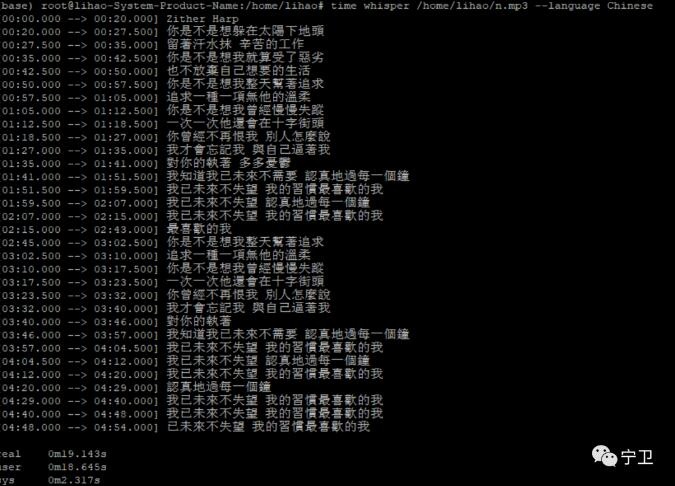
其使用的是torch,在生成过程中,默认的会生成对应的json、srt、tsv、txt、vtt等,如上图所示,近五分钟的录音识别过程是16.6秒左右,而小文件优势不是太大。
使用nvidia gpu来为ffmpeg(av-codec)进行运算加速
写到这里,感慨一下,曾经用过的卡内基的pocketsphinx,后边一直再没见有新的发布。